Abstract
Writing efficient parallel code for irregular data structures, such as graphs and sparse matrices, is notoriously difficult. Programmers must carefully balance load distribution, minimize synchronization overhead, and avoid subtle race conditions. While Large Language Models (LLMs) excel at generating sequential logic, they frequently fail in these high-performance parallel domains where correct abstractions, precise synchronization, and optimized memory access patterns are paramount. Current synthetic benchmarks primarily evaluate correctness on naive loops, ignoring the critical metric of runtime scaling (work-span) on complex data.
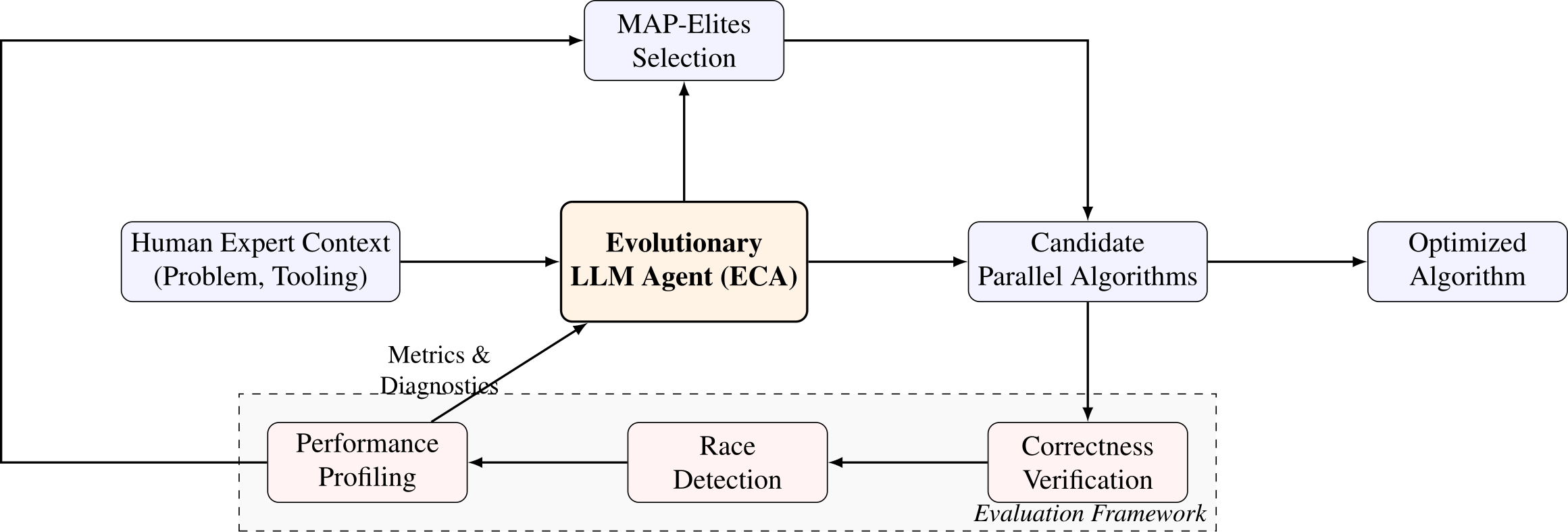
We bridge this gap with ParEVO, a framework designed to synthesize high-performance parallel algorithms for irregular data. Our contributions include: (1) The Parlay-Instruct Corpus, a curated dataset of 13,820 tasks synthesized via a "Critic-Refine" pipeline that explicitly filters for empirically performant algorithms that effectively utilize Work-Span DeepSeek (C++), Qwen (C++ & Rust), and Gemini (C++) models fine-tuned to align probabilistic generation with the rigorous semantics of the ParlayLib parallel data structures and algorithms library (and safe parallel Rust); and (3) an Evolutionary Coding Agent (ECA) that significantly improves the "last mile" of correctness by iteratively repairing code using feedback from compilers, dynamic race detectors, and performance profilers.
Methodology
Parlay-Instruct Corpus
A curated dataset of 13,820 tasks synthesized via a novel "Critic-Refine" pipeline that explicitly filters for algorithmic complexity and Work-Span optimality.
Specialized Models
We release fine-tuned versions of DeepSeek (6.7B) for C++, Qwen3 (30B) for C++, Qwen3 (30B) for Rust, and Gemini-2.5-Pro for C++ that internalize the high-level semantic abstractions (e.g. Map, Reduce, Scan) of modern parallel ecosystems like ParlayLib and Rust/Rayon.
Evolutionary Coding Agent (ECA)
Couples LLM mutations with genetic algorithms and MAP-Elites. Replaces typical unit-test fitness functions with deterministic hardware profiling, evaluating functional correctness, data-races, and actual execution speedups.
Key Results
On the ParEval benchmark, ParEVO achieves an average 106× speedup (with a maximum of 1103×) across the comprehensive suite. Specifically on highly complex irregular graph problems, ParEVO drives a robust 13.6× speedup.
Furthermore, our evolutionary approach matches state-of-the-art expert human-written baselines, achieving up to a 4.1× speedup on specific highly-irregular kernels (e.g., Maximal Independent Set), outperforming commercial models like GPT-5-Thinking and Gemini-3-Pro.
ParEval Average Speedup vs. Commercial Models
Runtime vs. Human Experts (PBBS / RPB)
Extended Performance Analysis: Strong Scaling
Maximal Matching (Rust)
Min. Spanning Forest (Rust)
FFT / DFT Scaling (C++)
Evolutionary Code Examples
Explore how ParEVO iteratively improves candidate parallel algorithms over multiple generations.
[cco16p1] DSU Iteration Optimization
Finding the root of a disjoint-set data structure.
// Loading Generation 1...// Loading intermediate generation...// Loading Generation 31...[coci08c6p5] Shortest Paths / Query Bucketing
Optimizing multi-source queries on an irregular grid.
// Loading Generation 1...// Loading intermediate generation...// Loading Generation 30...[coci21c3p2] Graph Representation & State Tracking
Optimizing BFS parent tracking on large graphs.
// Loading Generation 1...// Loading intermediate generation...// Loading Generation 32...Team
Liu Yang
Yale University
Zeyu Nie
Yale University
Andrew Liu
Yale University
Felix Zou
Yale University
Deniz Altinbüken
Google DeepMind
Amir Yazdanbakhsh
Google DeepMind
Quanquan C. Liu
Yale University